
")
As “camadas” de um ambiente SAP
Vamos discutir neste artigo a divisão técnica da arquitetura de um sistema SAP, ou seja, como dividimos os diferentes agentes responsáveis por receber as requisições, processá-las e devolver os dados. Podemos chamar esta divisão de SOFTWARE-ORIENTED VIEW. Quando falamos “arquitetura” estamos fazendo referência ao desenho de como o software é montado, como é distribuído. O fato é que o SAP é um sistema cliente-servidor de 3 camadas. Vale ressaltar que essas definições valem para qualquer sistema SAP, desde os mais antigos R/3 até os novos S/4, portanto, um Sistema SAP pode ser dividido em “camadas”, que agregam funções especificas dentro da infraestrutura do ambiente.
Essa divisão acontece para separar os diferentes tipos de tarefas que podem ser executadas no SAP. Cada camada representa uma entidade individual e pode ser tratada de forma separada. Entender como funcionam essas camadas é essencial para que possamos identificar problemas ou propor soluções que os usuários precisam. As camadas do SAP são as seguintes:
- Camada de apresentação: a parte de visualização dos dados (pode ser a parte da tela do usuário ou mesmo uma interface web)
- Camada de aplicação: camada responsável pelas regras de negócio e pela interação entre a tela (camada de apresentação) e o banco de dados (camada de banco de dados);
- Camada de Banco de Dados: interface que comunica com o Banco de Dados, executando as atualizações necessárias.
Uma informação vai trafegar da tela do usuário (SAP LOGON) até o SAP (camada de aplicação), ser processada e armazenada no banco de dados (camada de Banco de Dados).
Veja abaixo como é o desenho dessas camadas do SAP
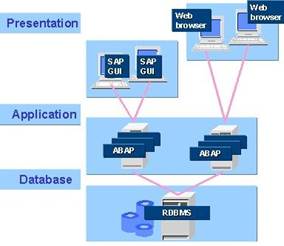
Camada de apresentação (Presentation Server)
Na camada de apresentação, temos o SAP LOGON como figura central. Nele o usuário irá ver as telas, informações e retornos que o SAP enviará. Muitas coisas acontecem na camada de apresentação e muita coisa se inicia nesta camada. As interfaces WEB também estão contidas nesta categoria.
Quando um usuário abre o seu SAP LOGON e inicia suas tarefas, ele está executando a camada de apresentação. Ele clica e digita dados nas diferentes telas, que são enviadas para a camada de aplicação. Esses dados são processados e devolvidos para a camada de apresentação para o usuário. Veja uma imagem do SAP LOGON 770 (também chamado de SAP GUI)
Lembrando que o SAP LOGON é a camada de apresentação de muitos dos produtos da SAP: ERP, CRM, BW, etc) e pode ser utilizado para acessar ambientes de Produção, Qualidade e Desenvolvimento.
Camada de aplicação (Aplication Server)
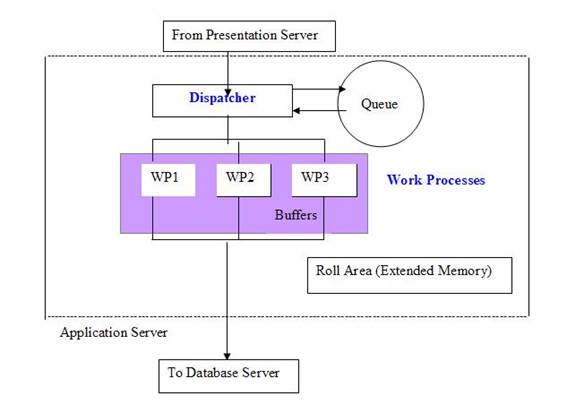
Para que a informação seja processada após sair da camada de apresentação, temos diferentes SOFTWARES. Esses SOFTWARES são chamados de WORK PROCESS. A camada de aplicação do SAP é basicamente formada por um DISPACTHER e vários WORK PROCESSES. O DISPACTHER é o responsável por distribuir as requisições para que os WORK PROCESSES executem.
A requisição do usuário entra no DISPATCHER, onde é armazenado em uma FILA (QUEUE). O DISPATCHER irá verificar a existência de um WORK PROCESS livre que possa processar a requisição e enviará o dado para ele, de acordo com o tipo de requisição e obedecendo a ordem de Firt-in, First-Out (primeiro que entra, primeiro que sai).
O DISPATCHER também é o responsável por gerenciar as principais áreas de memória do servidor. Duas dessas áreas merecem um comentário especial: A USER CONTEXT e a ROLL AREA.
A área de memória USER CONTEXT armazena informações relacionadas ao usuário que realiza a requisição, por exemplo: as autorizações do usuário, as configurações do usuário (Idioma, impressora padrão, etc), os nomes dos programas que estão sendo executados pelo usuário.
Quando um usuário executa o LOGON, uma área da USER CONTEXT é reservada para este LOGON. Quando o usuário efetua o LOGOFF, essa área é liberada.
A área de ROLL está relacionada a informações dos programas sendo executados por aquela requisição, como por exemplo os valores de variáveis e os ponteiros dos programas. Cada vez que um usuário inicia uma transação, uma ROLL AREA é criada para a instancia do programa relacionado. Quando o programa é finalizado, esta ROLL AREA é liberada.
Cada WORK PROCESS é ocupado por uma etapa do processamento da requisição, chamada de DIALOG STEP.
Funciona mais ou menos assim: o usuário abre uma transação, iniciando um DIALOG STEP. Neste início, o WORK PROCESS recebe os ponteiros da ROLL AREA e da USER CONTEXT, possibilitando que o WORK PROCESS acesse esses dados da memória para processar os dados do usuário e do programa solicitado. Ao processo de entrega dos ponteiros ao WORK PROCESS, chamamos de ROLL-IN. Esse processamento continua até que o programa envie uma tela para o usuário. Ao fim disso, os ponteiros são desalocados dos WORK PROCESSES. Este processo é chamado de ROLL-OUT. A partir disso, o WORK PROCESS está pronto para executar uma nova tarefa e o programa está ocupando apenas memoria do servidor e não consumindo CPU. Provavelmente o usuário olhará para a tela, se preparando para enviar novas requisições que seguirão este mesmo fluxo. Em caso de uma nova ação, novamente acontece o ROLL-IN (o DISPATCHER envia para um WORK PROCESS livre os ponteiros para acessar os dados da USER CONTEXT e da ROLL AREA) e depois do processo executado, o ROLL-OUT (a exclusão dos ponteiros do WORK PROCESS e a liberação dele para executar uma nova tarefa).
Quando o programa é finalizado, a ROLL AREA que ele estava ocupando é liberada. A USER CONTEXT permanece até que o usuário efetue LOGOFF.
Veja abaixo um desenho sobre como é a distribuição destes recursos na camada de aplicação:
Camada de banco de dados
Esta camada é a responsável por fazer a interface do ambiente com o Banco de dados, atualizando os dados a serem armazenados por um RDBMS (Relational Database Management System).
Textos de programas, definições de tela, menus, function modules, etc são armazenados em uma área específica do banco de dados, chamado de Repository, acessíveis pelo ABAP Workbench.
Agora que sabemos quais são as três camadas do dos sistemas SAP, podemos estudar com mais detalhes problemas que surgirem ou entender como determinado processo afeta o desempenho do ambiente. Quando entendemos essas informações básicas, fica muito mais fácil de avançar em análises objetivas, atuando realmente nos pontos que devem ser observados.
Posso colocar como exemplo quando o usuário reclama de lentidão no sistema: podemos identificar em qual camada acontece esta lentidão e aprofundar a análise, atuando, por exemplo apenas no Banco de dados, atuando na máquina do usuário ou mesmo ajustando parâmetros na camada de Aplicação.